WordPress的默认搜索是采用mysql的like,但是当我们整个网站的数据非常大的时候,mysql的like的效率将会非常慢,而且wordpress本身的性能也是比较低的,而且mysql like的准确率也不高,前一段时间本站使用了wordpress整合Google自定义搜索但是发现Google经常被墙,很不爽,决定改之。今天wordpress教程网跟大家分享下如何在wordpress中使用高效的全文索引组件coreseek。Coreseek开源中文检索引擎,可以说是sphinx中文版,因为coreseek加入了中文分词库,大家可以到官网去查看具体介绍:http://www.coreseek.cn/。如果你的wordpress系统搜索要采用coreseek,首先你得拥有自己的服务器(VPS),如果你只是ftp空间那是没有办法的。本站已成功部署,你可以在本站搜索中查看实例。下面就让我们一步步来部署吧。
安装coreseek
coreseek的安装建议直接查看官网的安装方法,如果linux系统可以直接查看:http://www.coreseek.cn/products-install/install_on_bsd_linux/,其他系统可以查看:http://www.coreseek.cn/products-install/#doc_cn,本站给出我的配置文件etc/csft.conf,配置信息如下:
#MySQL数据源配置,详情请查看:http://www.coreseek.cn/products-install/mysql/
#配置来着wordpress教程网(http://www.dba.cn)
#请先将var/test/documents.sql导入数据库,并配置好以下的MySQL用户密码数据库
#源定义
source mysql
{
type = mysql
#mysql数据配置
sql_host = localhost
sql_user = root #mysql用户名
sql_pass = #mysql密码
sql_db = wpux
sql_port = 3306
sql_query_pre = SET NAMES utf8
sql_query = SELECT ID, UNIX_TIMESTAMP(post_date) AS date_added, post_content, post_title FROM wp_posts
#对wp_posts表建立全文索引
#sql_query第一列id需为整数
#post_title,post_content两个字段被全文索引
#sql_attr_uint = ID #从SQL读取到的值必须为整数
sql_attr_timestamp = date_added #从SQL读取到的值必须为整数,作为时间属性
sql_query_info_pre = SET NAMES utf8 #命令行查询时,设置正确的字符集
sql_query_info = SELECT * FROM wp_posts WHERE ID=$ID #命令行查询时,从数据库读取原始数据信息
}
#index定义
index mysql
{
source = mysql #对应的source名称
path = var/data/mysql #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
docinfo = extern
mlock = 0
morphology = none
min_word_len = 1
html_strip = 0
#中文分词配置,详情请查看:http://www.coreseek.cn/products-install/coreseek_mmseg/
charset_dictpath = /usr/local/mmseg3/etc/ #BSD、Linux环境下设置,/符号结尾
#charset_dictpath = etc/ #Windows环境下设置,/符号结尾,最好给出绝对路径,例如:C:/usr/local/coreseek/etc/...
charset_type = zh_cn.utf-8
}
#全局index定义
indexer
{
mem_limit = 64M #内存设置
}
#searchd服务定义
searchd
{
listen = 9312
read_timeout = 5
max_children = 30
max_matches = 1000
seamless_rotate = 0
preopen_indexes = 0
unlink_old = 1
pid_file = var/log/searchd_mysql.pid #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
log = var/log/searchd_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
query_log = var/log/query_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
}
你可以直接拷贝该代码到你的coreseek安装目录下的 etc/csft.conf文件中,以上配置你可以直接拷贝使用,只有mysql的数据库信息进行修改即可。
这边提醒大家注意几点:
1、要先安装赖库。
2、安装支持mysql的数据源,wordpress是采用mysql数据库的。
3、常用的命令如下:
a.开启coreseek命令
/usr/local/coreseek/bin/searchd -c etc/csft.conf
以下为正常开启搜索服务时的提示信息:(csft-4.0版类似)
Coreseek Fulltext 3.2 [ Sphinx 0.9.9-release (r2117)]
Copyright (c) 2007-2010,
Beijing Choice Software Technologies Inc (http://www.coreseek.com)
using config file ‘etc/csft.conf’…
listening on all interfaces, port=9312
b.如要停止搜索服务,请使用
/usr/local/coreseek/bin/searchd -c etc/csft.conf --stop
c.如要已启动服务,要更新索引,请使用
/usr/local/coreseek/bin/indexer -c etc/csft.conf --all --rotate
你可以把这个命令加到定时任务中,如
crontab -e 然后加入以下定时任务 00 03 * * * /sbin/service sshd stop #意思是每天凌晨3:00重建索引。
注意:如果大家数据量大的话可以采用增量索引与实时索引等,大家可以到官网去查看手册。
OK,至此我们的coreseek已经安装完成
wordpress全文搜索页面
1、在解压的coreseek的文件中大家可以看到有个testpack目录,进入testapck/api我们可以看到有很多接口文件。我们可以直接拷贝这个api目录到我们的主题目录下,呆会搜索页面将会使用到该文件:
cd coreseek-3.2.14/testpack/api ll 我们可以看到api的目录文件如下 drwxrwxrwx 2 root root 4096 Jan 12 2011 java java接口 drwxrwxrwx 2 root root 4096 Jan 12 2011 libsphinxclient drwxrwxrwx 5 root root 138 Jan 12 2011 ruby -rwxrwxrwx 1 root root 44399 May 7 2010 sphinxapi.php php接口 -rwxrwxrwx 1 root root 26251 May 7 2010 sphinxapi.py -rwxrwxrwx 1 root root 1053 May 7 2010 test2.php php测试文件 -rwxrwxrwx 1 root root 652 May 7 2010 test2.py -rwxrwxrwx 1 root root 763 Jan 12 2011 test_coreseek.php -rwxrwxrwx 1 root root 5656 Jun 8 2010 test.php -rwxrwxrwx 1 root root 3377 May 7 2010 test.py
以下的文件对我们有用的就是sphinxapi.php,他是coreseek的php调用接口,test.php与test2.php是全文索引的测试文件,大家可以参考下,其他文件可以删除。将api目录复制到我们的主题目录后,我们在搜索页面search.php中全文索引的代码如下:
<?php
//coreseek搜索结果
include_once( dirname(__FILE__) . "/api/sphinxapi.php" );
$cl = new SphinxClient ();
$cl->SetServer ( '127.0.0.1', 9312);
//以下设置用于返回数组形式的结果
$cl->SetArrayResult ( true );
$paged = (get_query_var('paged')) ? get_query_var('paged') : 1;
$start = ($paged - 1) * 10;
$cl->SetLimits($start,10);
$keyword = $s = isset($_GET['s']) ? htmlspecialchars(trim($_GET['s'])) : ''; //获取搜索词
$res = $cl->Query ( "$keyword", "*" );
//print_r($res); //查看全文索引结果
$total = $res['total']; //所有返回文章数,用于分页
if(!empty($res['matches'])) {
foreach($res['matches'] as $value) {
$id_arr[] = $value['id'];
}
}
$id_str = implode(",", $id_arr);
$args = array();
$args = array(
'include' => $id_arr
);
wp_reset_query();
$sql = "select * from wp_posts where ID in($id_str) and post_type='post' AND post_status = 'publish'"; //根据ID读取文章数据
$data = $wpdb->get_results($sql); //输出数据,之后你可以使用foreach数据$post object
if( is_search() && empty($id_arr)) { echo '暂无搜索结果!'; }else{
foreach($data as $post) {
echo get_the_title($post); //输出文章标题
}
}
?>
...
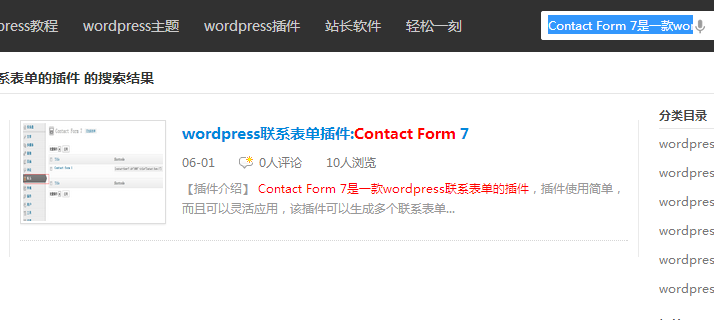
OK!大功告成,有什么问题大家可以留言讨论,实际应用请查看本站,如下图: